Abstract 뜯어보기
We expose and analyze several of its characteristic artifacts, and propose changes in both model architecture and training methods to address them
- stylegan2에서는 지난 버전에서 몇 가지 특징적인 결함들을 분석했고, 이에 대한 방법으로 모델 구조와, 훈련 방법에 있어 변화를 제안한다.
In particular, we redesign the generator normalization, revisit progressive growing, and regularize the generator to encourage good conditioning in the mapping from latent codes to images. In addition to improving image quality, this path length regularizer yields the additional benefit that the generator becomes significantly easier to invert.
- latent code -> image로 맵핑하는 데 더 좋은 영향을 주는 요소들
- generator의 normalization 부분을 수정했고,
- progressive growing(기존 stylegan에서 해상도를 한 step씩 올려가며 학습하는 것)을 재고하고,
- generator를 정규화했다.
We furthermore visualize how well the generator utilizes its output resolution, and identify a capacity problem, motivating us to train larger models for additional quality improvements
- 출력물의 해상도를 얼마나 잘 활용하는지 시각화하여 수용량의 문제를 발견했고, 이에 따라 추가적인 품질 향상을 위해 수용력이 더 큰 모델을 이용해 학습하게 됐다.
1. Introduction
stylegan이 생성한 이미지에서 발견되는, 인공적으로 보이는 특징적인 결점이 발생하는 원인 2가지
- common blob-like artifacts, and find that the generator creates them to circumvent a design flaw in its architecture
- redesign the normalization used in the generator, which removes the artifacts
- 모양보단 텍스쳐에 집중하는 metric인 FID and P&R은 이미지의 품질을 정확하게 평가하기 어렵다.
- latent space interpolation 품질을 측정하기 위해 고안된 PPL(Pereceptual Path Length)이 형태의 일관성이나 안정성과도 상관관계가 있다.
- 위 사실에 근거해서, synthesis network를 정규화(regularize)해서 좀 더 mapping이 부드럽게 되게 했고, 품질에서 분명한 향상을 이룸
- original stylegan의 generator에 비해 path-length로 정규화된 stylegan2의 [projection : image -> W (latent Space)] 이 훨씬 더 성능이 좋음을 발견했다.
- 이미지가 소스로부터 생성되기 쉽게 만듦
2. Removing normalization artifacts

feature map을 보면, 64x64 해상도부터 물방울 같은 결함이 보이기 시작하고, 모든 해상도에 이게 다 보임, 게다가 해상도가 높아질수록 점점 더 강하게 나타남. 판별자(discriminator)가 이걸 잡아낼 텐데도 불과하고, 왜 이게 일관되게 나타났는지는 미지수다.
문제는 AdaIn(adaptive instance normalization)이다. feature map마다 각 평균과 분산으로 normalization 한다. 그런데 이게 잠재적으로 feature들 사이에 상대적인 크기에서 발견되는 정보들을 파괴한다.
위 사항에 대해 파악하기 위해 가설을 세웠다. generator가 의도적으로 몰래 이전의 instance normalization에 강한 신호를 준다. 강력하고 국소적인 spike를 만들고 이게 통계에 강한 영향을 미쳐서, generator가 효과적으로 그 신호를 모든 곳에 scale 할 수 있게 만든다는 말이다. 이 가설은 다음 과정에 의해 설득력을 얻는다. normalization 단계를 제거하면, 물방울 결함이 완전히 사라졌다! (내 생각엔 이 과정이 반대로 일어났을 것 같다. 어찌하다가 normalization 없앴는데 물방울이 사라짐 -> normalization이랑 저 결함이 무슨 관계가 있을까? -> 가설 나옴, 즉 짜 맞춘 거 같다.)

2.1. Generator architecture revisited
AdaIn을 2개 파트로 나눔 : Normalization + modulation
original stylegan에서는 style block 내부에 bias랑 noise를 적용했는데, 이게 현재 스타일의 크기와 반비례하는 효과를 주게 만들었다.
그래서 style block 밖에다가 이 과정을 뺏는데, 결과가 더 좋았다. 또 normalize 할 때, 평균까진 필요 없었고, 표준편차만 있으면 충분했다.
처음 Input에다가 bias, noise, normalization을 제거해도 안전한 걸 확인함. 이런 변화과정을 반영한 게 새로운 generator 구조다.
2.2. Instance normalization revisited
original style gan은 style mixing으로 생성 이미지를 조절하는 능력이 강점이었다. (인퍼런스 시에 다른 w를 다른 layer들에 feeding 하는 방식) 실제로는 스타일 조작이 특정 핓 맵들을 증폭시킬 수 있다. 스타일 믹싱을 제대로 하려면, 샘플마다 bias에서 증폭되는 정도에 반대로 행동하게 만들어야 했다. 아니면 이어진 레이어들이 의미 있게 작동 못한다.
scale-specific 한 조절을 포기해서, normalization을 간단히 제거할 수 있었고, 그 결과 결함을 제거함과 더불어 FID도 조금 향상됐다. 핵심 아이디어는 투입되는 피쳐 맵의 예상 통계치에 대해 normalization을 하되, 강제하지 않는 거다.
modulation 효과는 무엇? modulation 다음에 conv가 오는데, modulation은 입력 스타일에 근거한 conv의 각 피쳐 맵을 scaling 해준다.

instance normalization의 본래 목적은 conv 출력 피쳐 맵들의 통계량에서 scaling의 영향을 제거하는 거다. 이건 직접으로 바로 할 수 있다! 입력값에 대한 활성화는 독립 항등 분포를 따르고 정규 표준 편차를 띄는 임의의 변수라고 가정한다. modulation과 convolution 이후엔 출력 값의 활성화는 아래와 같은 표준 편차를 같게 된다.
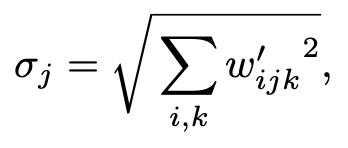
뒤에 나오는 normalization은 결과가 다시 정규 표준 편차를 띄게끔 다시 회복? 조정해준다.

결과적으로 그림 1-d에서 보듯이, 식 1과 식 3이 s를 이용해서 단일 conv layer의 가중치를 수정해주는 것으로 전체 style block을 bake 했다.
instance norm과 비교하면, demodulation 테크닉은 좀 약하다. 왜냐하면 피쳐 맵의 실제 내용물 대신에, 신호에 대한 가정을 근거로 하기 때문이다. 유사한 통계 분석이 현대에 네트워크 초기화에 광범위하게 쓰이고 있지만, data-dependent 한 normalization 기법의 대안으로 이게 이전에 쓰였단 건 알지 못했다. 이 demodulation은 weight normalization이랑도 관련 있는데, weight tensor를 재매게화(reparameterize)한 다는 점에서 그렇다.
결과적으로 새로운 디자인은 인공적인 결함을 제거하면서도 완전한 controllability를 갖췄다.
3. Image quality and generator smoothness


원래 PPL(perceptual path length)는 latent space에서 동요, 섭동(perturbations)과 생성 이미지 사이의 평균 LIPIS 거리를 측정함으로써, latent space로부터 생성된 이미지로 맵핑되는 과정이 얼마나 부드럽게 이루어졌는지 정량적으로 측정하기 위해 도입된 metric이었다.
근데 이게 낮을수록 이미지 품질이 높다. 이게 직관적으로 분명하지 않아서, 가설을 세우고 또 뭔가를 했다. 블라블라~
PPL을 최소가 되게끔 단순하게 만들 순 없는데, 그렇게 하면 generator가 재현율이 0인 퇴화된 solution이 돼버리기 때문이다. 대신에, 새로운 regulaizer를 도입했다. 이 정규화는 generator의 mapping을 결함 없이 더 부드럽게 하는 걸 목표로 한다. 이 정규화 항은 좀 계산하는 데 비용이 좀 들지만, 우선 어떤 정규화 tecnique에도 적용 가능한 일반적인 최적화를 설명할 거다.
3.1. Lazy regularization
main loss와 정규화 항이 하나의 식으로 표현되고, 동시에 최적화가 이루어진다. 이때 정규화 항이 메인 항보다 덜 계산될 수 있단 걸 관찰했다. 이에 따르면, 계산 비용과 메모리를 상당히 절감할 수 있게 된다.
3.2. Path length regularization
W에서의 고정된 크기의 움직임이, 이미지에 있어서 0이 아닌 고정된 크기의 변화를 유발하게 만들고 싶었다. 이미지 공간에서 임의의 방향으로 움직이고, 그에 따른 w의 기울기 변화량을 관찰했고, 이걸 앞서 우리가 원한다고 했던 이상적인 조건과 비교해 차이를 측정했다. 이 기울기들은, w 또는 이미지의 특정 방향에 관계없이, 같은 길이에 가까웠다. 이는 latent space에서 이미지로 mapping 하는 게 well-conditioned 함을 나타낸다.

블라 블라... 생략
실제로, ppl이 더 모델에 이상적으로 작동하는 걸 발견했다. 더 부드러운 generator는 역변환도 상당히 쉬었다.
4. Progressive growing revisited
Progressive growing은 고 해상도 이미지 합성엔 성공적이었으나, 고유한 인위적인 결함 같은 특징을 유발했다. 중요한 점은 점진적으로 성장한 generator는 세부사항에 대해서 강한 위치 선호를 나타낸다는 것이다.

4.1. Alternative network architectures

skip connections in the generator drastically improve PPL in all configuration.
generator에서 skip connection은 유용하다!
a residual discriminator network is clearly beneficial for FID.
discriminator에서 residual은 유용하다!
we use a skip generator and a residual discriminator, without progressive growing.
그래서 progressive growing 없이 각각 skip generator, residual discriminator를 쓴다.
4.2. Resolution usage
progressive growing에서 보존하길 원했던 핵심 측면은, generator가 초기에 저해상도 피쳐들에 집중하다가 서서히 미세한 세부사항들에 관심을 기울이게 하는 것이다. Figure7에서 나오는 구조는 generator가 첫 번째 저해상도 이미지가 고해상도 레이어에 영향을 받지 않고 출력할 수 있게 만들고, 학습이 진행되면서 나중엔 고해상도에 집중하게 한다. 이건 강제하는 게 아니라서, generator가 이득이 있을 때만 이렇게 할 것이다.
실험을 하다가 pixel level에서 세부사항을 놓치는 걸 확인했고 512 버전 대신 1024 버전으로 좀 더 정확하게 만들려 했다. 이걸 토대로, 네트워크 수용량에 문제가 있다고 가설을 세웠다. 두 네트워크 가장 높은 해상도 레이어에 있는 피쳐 맵 개수를 두배로 하고 테스트했다. 아래 그림에서 8(b)에서 고 해상도 레이어의 기여 정도가 크게 늘었다.

또한 아래 표는 LSUN 네 가지 카테고리 별로 stylegan과 stylegan2의 성능을 비교한 거다. FID와 PPL에서 상당한 성능 향상을 볼 수 있다. 사이즈를 더 키우면 더 효과가 좋을 수도 있다.

5. Projection of images to latent space
합성 네트워크 g를 역변환하는 건 많은 응용이 가능한, 흥미로운 문제다. 우선 latent feature 공간에서 주어진 이미지를 조작하려면 그와 매칭 되는 latent code w를 먼저 찾아야 한다. 몇몇 실험에서 공통적인 latent code w보다 generator의 각 레이어에 맞게 개별 w를 선택하는 게 더 좋은 성능을 나타냄을 보였다.... 그런데 이렇게 확장시키면 또 뭔가 문제가 있다.
그래서, 확장되지 않은 latent space, 즉 original에서 latent code를 찾는 것에 집중했다.
투영 방식이 기존과 두 가지 면에서 다르다.
1. 최적화 과정에서 latent code에 ramped-down noise를 더했다. 더 복잡한 latent space를 탐색하게 하려고.
2. generator에 입력되는 stochastic noise 값도 정규화(regularize)시켜서 신호 간의 간섭을 막도록, 최적화했다.
5.1. Attribution of generated images

original은 배경이 특히 다르다. 생성된 이미지를 다시 투영시켜 생성하는 건 거의 완벽히 똑같다. 그런데 학습 세트에 있는 실제 이미지를 투영시키고 다시 합성한 거와 실제 이미지는 분명한 차이가 있다.

투영 후 합성한 이미지와, 원래 이미지 사이의 LPIPS 거리를 계산해서 투영이 얼마나 잘 됐는지 측정했다. stylegan2가 생성 이미지와 실제 이미지 사이의 분포 사이에 거리가 있어 보인다. 거리가 클수록 투영이 더 잘 됨을 나타내는 듯하다.
정확한 건, LPIPS 거리에 대한 이해가 필요하다.
LPIPS 거리는 [Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. In Proc. CVPR, 2018.] 이 논문 참고 필요
아무튼 stylegan2에 이미지 퀄리티도 더 높고, 역변환도 더 잘한다.
6. Conclusions and future work
이미지 품질 개선, 역변환도 더 쉽다.
학습 성능도 향상됨.
stylegan은 초당 37장 NVIDIA DGX-1 with 8 Tesla V100 GPUs
weight demodulation 덕분에 데이터 플로우 단순화, lazy regularization, 코드 최적화에서 속도 향상의 대부분이 이루어짐
초당 61장 학습 (40% 이상 빠름)
stylegan2, 더 큰 네트워크 이용 시엔 초당 31장 학습, 조금 더 비용이 더 든다.
FFHQ 학습하는 데 9일, LSUN CAR 학습하는 데는 13일 걸림
path length regularization에 대한 연구, eg) 픽셀 공간에서 L2 거리를 데이터에 기반한 피쳐 공간의 metric으로 대체
적용에 있어선 학습 데이터 관련 축소도 필요. 실제 적용할 때, 많은 intrinsic variation을 포함한 수 만 장의 샘플을 얻는 게 불가능하기 때문이다.



