coursera 강의를 정리해서 스스로 이해를 돕기 위해 만든 자료입니다.
#데이터를 생성하고,
dataset = tf.data.Dataset.range(10)
# tf.data.Dataset.window를 이용하여 특정 window 사이즈만큼의 크기를 갖는 데이터를 얻는다.
drop_remainder를 true로 할 경우 window 사이즈보다 작은 데이터는 다 drop된다.
dataset = dataset.window(5, shift=1, drop_remainder=True)
# flat_map 함수를 이용하여 <_VariantDataset shapes: (), types: tf.int64> 타입의 데이터를 tf.Tensor([0 1 2 3 4], shape=(5,), dtype=int64)로 바꿔준다.
dataset = dataset.flat_map(lambda window: window.batch(5))
# dataset에 각각 입력, 라벨로 나눠진 tuple값을 반환하게끔 하는 lambda 함수를 map한다.
dataset = dataset.map(lambda window: (window[:-1], window[-1:]))
# shuffle을 통해 무작위로 섞어준다.
dataset = dataset.shuffle(buffer_size=10)
# batch 크기 2만큼의 데이터셋을 로드한다. prefetch는 안해도 되지만 아래에서 하는 이유를 설명
dataset = dataset.batch(2).prefetch(2)
for x,y in dataset:
print("x = ", x.numpy())
print("y = ", y.numpy())
prefetch?
-
This allows later elements to be prepared while the current element is being processed. This often improves latency and throughput, at the cost of using additional memory to store prefetched elements.
-
현재 batch를 처리하는 중에, 다음 batch를 추가적인 메모리를 사용해서 준비해 놓는다. 속도 향상 기대가능
-
batches. examples.prefetch(2) will prefetch two elements (2 examples), while examples.batch(20).prefetch(2) will prefetch 2 elements (2 batches, of 20 examples each).
Sequence bias
-
가령 어떤 영화가 좋냐고 물어보면서 '조폭 마누라', '쿵푸팬더', '반지의제왕' 이렇게 3가지를 제시하면, 첫번째로 들은 답에 만약 친숙하다면, 첫번째 나온 선택지를 답할 확률이 높다. 이를 sequence bias라 한다.
Notebook
- windowed_dataset이란 함수를 정의한다.
- numpy series로 부터 from_tensor_slices를 이용하여 데이터 tf.data.Dataset 객체를 생성한다.
- window 함수를 이용하여 window_size+1크기 만큼씩 데이터 형태를 바꿔준다.
- flap map을 이용하여 tensor 객체로 변환해주고
- (input, label) tuple 형태로 map을 시켜준다. 이때 전체 데이터에 대해서 shuffle하는게 아닌 shuffle_buffer 크기만큼만 shuffle을 해주기 때문에 속도가 빠르다.
- shuffle된 결과에 대해 batch_size만큼 호출해주도록 준비해준다.

- DNN model을 정의하고, 학습한다.
- 첫번째 Dense layer의 경우 input_shape를 지정해준다. [window_size]로 해서 window_size 만큼의 input이 들어오게 된다.
- complie을 해준다.
- model.fit으로 학습을 한다!
- 모델 예측을 해보고, 결과를 그려본다.
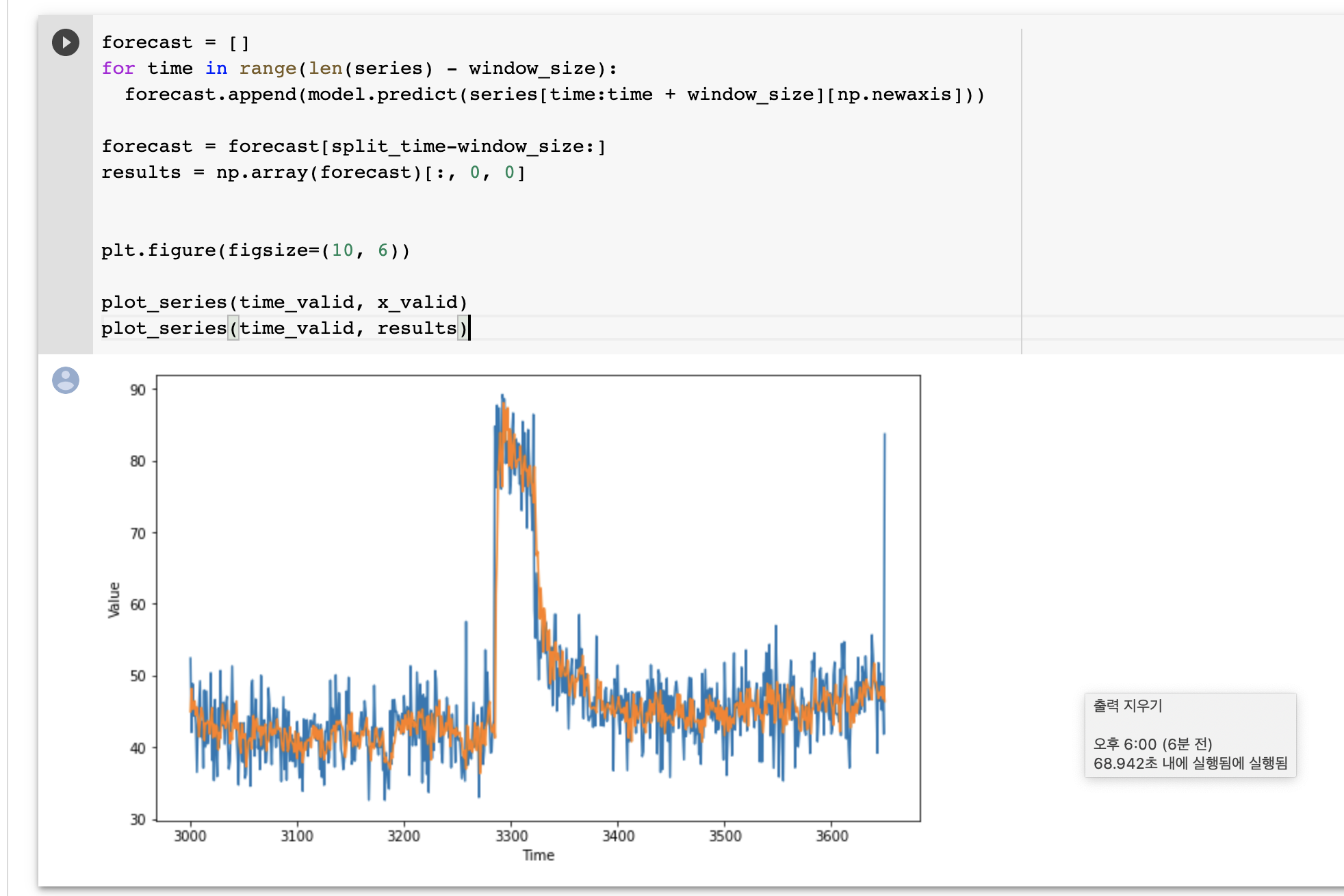 주황색 선이 예측값, 파란 선이 실제 값이다.
주황색 선이 예측값, 파란 선이 실제 값이다. 예측 값이 좋지 못하다. lr을 조절해서 최적의 lr로 다시 학습하고 결과를 산출하자.
예측 값이 좋지 못하다. lr을 조절해서 최적의 lr로 다시 학습하고 결과를 산출하자. - callbacks 내의 LearningRateScheduler 객체를 만든다. epoch에 따라 lr을 조절하는 callback이다. 이걸 fit할 때 callbacks에 할당하고 학습해준다. fit 결과를 history로 받아, lr애 따른 loss를 plot해준다.
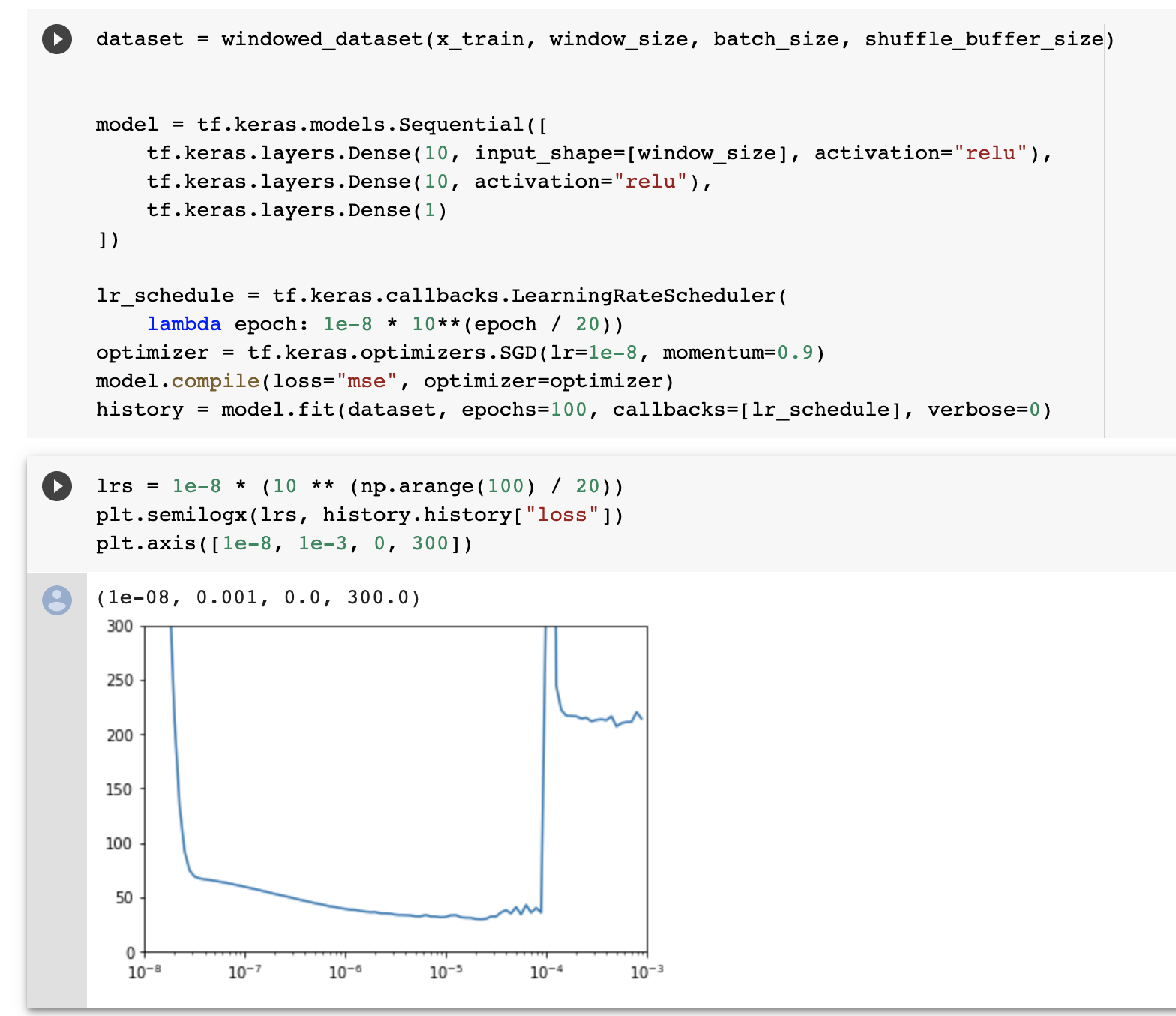
- 2* 10-5 정도가 가장 좋은 lr로 보인다. 이를 이용해 다시 학습한다.

- 더 결과가 안 좋다... 정답을 보니 첫번째 Dense Layer를 1000개쯤 줬다.
Quiz)
-
What is a windowed dataset?
-
A consistent set of subsets of a time series (x)
-
The time series aligned to a fixed shape (x)
-
A fixed-size subset of a time series (o)
-
-
If you want to inspect the learned parameters in a layer after training, what’s a good technique to use?
-
Decompile the model and inspect the parameter set for that layer (x)
-
Run the model with unit data and inspect the output for that layer (x)
-
Assign a variable to the layer and add it to the model using that variable. Inspect its properties after training (o)
-
-
If you want to amend the learning rate of the optimizer on the fly, after each epoch, what do you do?
-
Use a LearningRateScheduler and pass it as a parameter to a callback (x)
-
Use a LearningRateScheduler object in the callbacks namespace and assign that to the callback (o)
-

www.tensorflow.org/api_docs/python/tf/data/Dataset#prefetch
tf.data.Dataset | TensorFlow Core v2.3.0
Represents a potentially large set of elements.
www.tensorflow.org



