style gan loss 이해하기 위해, 여기에 쓰인 WGAN-GP loss를 살펴볼까 한다. 우선 GAN loss, WGAN loss의 차이를 살펴보고 WGAN loss를 이해한다면 WGAN-GP loss도 이해할 수 있다. 수식적으로 깊게 들어가진 않는다. 얕게!
GAN vs WGAN

위 그림을 보면 GAN과 WGAN의 차이를 확연하게 알 수 있다. GAN의 Discriminator와 유사한 역할을 하는 게 Critic이다. 그런데 discriminator의 경우 출력 값으로 확률 값이 필요하기에 Logistic Sigmoid function을 마지막 logit에 취해줘야 했다. Critic의 경우 이게 없다.

대신 f 가 추가 되는데, 위에서 f는 1-Lipschitz function이다. 이 조건을 맞추기 위해 WGAN에선 clipping을 이용해서 f에서 wight의 최댓값을 제한다.
- 1-립셔츠 조건 (1-Lipschitz condition/constraints)

위 수식을 만족하는 함수 f를 1-립셔츠 함수라고 한다.
WGAN을 좀 더 살펴보자.

- 기존 간은 두 분포가 같은 지 간단하게만 나타내 주는데, wgan은 두 분포가 얼마나 유사한 지를 wasserstein distance를 통해 알려준다.
- 기존 GAN은 생성 이미지가 real 인지 fake인지 분류하거나, real 혹은 fake일 확률을 계산한다. 그런데 WGAN은 주어진 이미지의 realness 혹은 fakeness를 점수화한다.
- discriminator는 입력 데이터가 real 인지 fake인지를 판별하고 학습할수록 판별이 더 정확해진다. 하지만 critic은 립셔츠 함수가 더 정확한 거리를 얻게끔 simulation을 하는데, 이를 이용해 Wassertein distance를 더 잘 측정할 수 있게 된다.
- 이때 simulation은 critic network가 립셔츠 연속 조건을 만족시킨다는 implicit한 제약 조건 상에서 시행된다. 최종적으로 나온 공식을 보면 GAN에 비해 WGAN이 훨씬 더 간단해 보인다. 그냥 두 평균의 차이이다.

알고리즘?
- WGAN의 loss는 real과 fake의 점수 차이를 최대화하는 방식으로 작동한다.
- 아래 알고리즘에서 보듯이, 우선 두 이미지를 비교한다. (fake, real). for 문을 돌면서 critic network에서 fake, real의 점수를 구하면, 두 점수의 기댓값의 차이를 최대화하는 방식으로 critic network가 학습된다. 이 차이가 바로 wassertein 거리인데 이 값은 실제 정확한 거리가 아닐 수 있지만, 가능한 유사하게 산출된다.

요약하면
-
Critic Loss = [average critic score on real images] – [average critic score on fake images]
-
Generator Loss = -[average critic score on fake images]
GAN VS WGAN 학습 영향?
아래 그림은 GAN과 WGAN의 차이를 잘 보여주는데, WGAN의 경우 GAN에 비해 더 부드러운 기울기 값을 가지는 걸 볼 수 있다. 그 결과 generator 학습이 훨씬 잘된다!

WGAN-GP (Wassertein GAN with gradient penalty)
WGAN-GP의 경우 WGAN이 립셔츠 조건을 만족시키기 위해 cliping을 한 거완 다르게, 다른 방식으로 이 조건을 만족시킨다. 그걸 Penalization이라고 하는데, critic network의 가중치에 penalty를 주는 것이다.

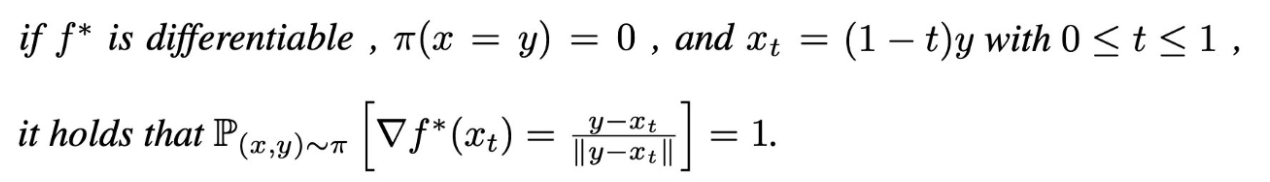
real, fake data 사이에 interpolated된 점들은 f에 대해 gradient의 크기가 1을 만족해야 한다.

WGAN_GP 알고리즘

style gan에 반영된 wgan-gp (pytorch 코드)
# critic(discriminator) 학습
if args.loss == 'wgan-gp':
## -D_w(x)라고 보면됨 (realness score)
real_predict = discriminator(real_image, step=step, alpha=alpha)
real_predict = real_predict.mean() - 0.001 * (real_predict ** 2).mean()
(-real_predict).backward()
fake_image = generator(gen_in1, step=step, alpha=alpha)
fake_predict = discriminator(fake_image, step=step, alpha=alpha)
if args.loss == 'wgan-gp':
## D_w(x~)라고 보면됨 (fakeness score)
fake_predict = fake_predict.mean()
fake_predict.backward()
## 아래부터는 gradient penalty항
# real과 fake 사이에 interpolated된 점들 : x_hat
eps = torch.rand(b_size, 1, 1, 1).cuda()
x_hat = eps * real_image.data + (1 - eps) * fake_image.data
x_hat.requires_grad = True
hat_predict = discriminator(x_hat, step=step, alpha=alpha)
# hat_predict의 gradient의 norm이 1이 되도록 규제해야한다.
grad_x_hat = grad(
outputs=hat_predict.sum(), inputs=x_hat, create_graph=True
)[0]
grad_penalty = (
(grad_x_hat.view(grad_x_hat.size(0), -1).norm(2, dim=1) - 1) ** 2
).mean()
# grad_penalty에 곱해지는 상수 lambda : 10 (논문에 나옴)
grad_penalty = 10 * grad_penalty
grad_penalty.backward()
if i%10 == 0:
grad_loss_val = grad_penalty.item()
disc_loss_val = (-real_predict + fake_predict).item()
# generator 학습
requires_grad(generator, True)
requires_grad(discriminator, False)
fake_image = generator(gen_in2, step=step, alpha=alpha)
predict = discriminator(fake_image, step=step, alpha=alpha)
if args.loss == 'wgan-gp':
## critic으로 산출한 fakeness score만 최소화 하면 됨.
loss = -predict.mean()
loss.backward()
참고 사이트
How to Implement Wasserstein Loss for Generative Adversarial Networks
The Wasserstein Generative Adversarial Network, or Wasserstein GAN, is an extension to the generative adversarial network that both improves the stability when training the model and provides a loss function that correlates with the quality of generated im
machinelearningmastery.com
https://arxiv.org/abs/1701.07875
Wasserstein GAN
We introduce a new algorithm named WGAN, an alternative to traditional GAN training. In this new model, we show that we can improve the stability of learning, get rid of problems like mode collapse, and provide meaningful learning curves useful for debuggi
arxiv.org
https://arxiv.org/pdf/1704.00028.pdf
https://medium.com/@jonathan_hui/gan-wasserstein-gan-wgan-gp-6a1a2aa1b490
GAN — Wasserstein GAN & WGAN-GP
Training GAN is hard. Models may never converge and mode collapses are common. To move forward, we can make incremental improvements or…
medium.com
https://kionkim.github.io/2018/07/26/WGAN_3/
From GAN to WGAN
This post explains the maths behind a generative adversarial network (GAN) model and why it is hard to be trained. Wasserstein GAN is intended to improve GANs’ training by adopting a smooth metric for measuring the distance between two probability distri
lilianweng.github.io
[논문읽기] 11. WGAN-GP : Improved Training of Wasserstein GANs
< WGAN-GP : Improved Training of Wasserstein GANs > " style="clear: both; font-size: 2.2em; margin: 0px 0px 1em; color: rgb(34, 34, 34); font-family: "Roboto Condensed", Tauri, "Hiragino Sans GB", "..
leechamin.tistory.com
'Data-science > 논문 읽기' 카테고리의 다른 글
| gan 논문에 등장하는 artifact 뜻? (0) | 2020.10.04 |
|---|---|
| 논문에 등장하는 revisit 뜻? (0) | 2020.10.04 |
| [Deep learning 논문 읽기] style-gan 1 (0) | 2020.08.26 |
| [딥러닝 논문 리뷰] A Spatio-Temporal Spot-Forecasting Framework for Urban Traffic Prediction - 1 (0) | 2020.06.22 |
| ablation study가 뭐냐 대체... (0) | 2019.05.03 |
