기본적인 인코딩&디코딩
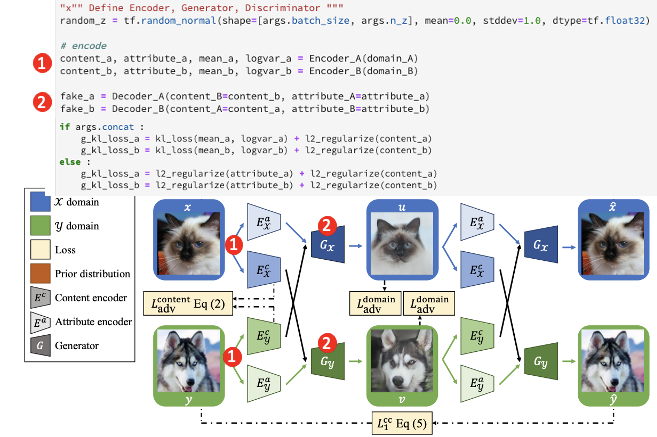
우선 도메인 A에 있는 이미지들이 인코더 A를 통과하여 콘텐츠 latent vector와 특성 latent. Vector를 출력합니다.
B도 마찬가지로 진행합니다.
이후 콘텐츠 latent vector를 서로 교차하여 넣어주고, 특성 latent vector는 각 도메인에 맞게 Generator에 넣어줍니다.
A Generator의 경우 도메인 a 특성 latent vector, b 콘텐츠 latent vector를 입력 값으로 받는다고 보시면 됩니다. B Generator의 경우 반대입니다.
Reconstruction 과 랜덤 이미지 생성
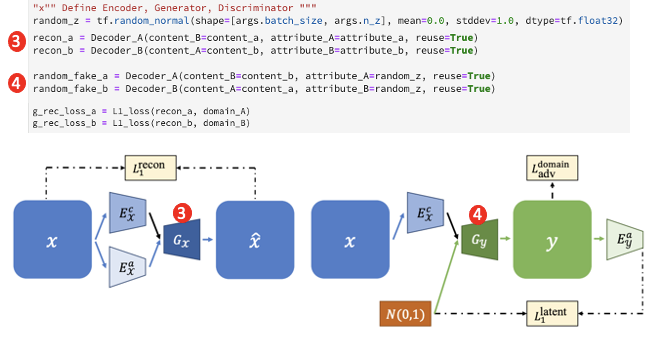
3의 경우 Reconstruction loss를 위한 항입니다. A 도메인 본래의 특성 latent, 콘텐츠 latent를 A Generator가 입력으로 받습니다. 그렇게 해서 생성하는 이미지는 reconstruction된 A 도메인 이미지입니다. B도 마찬가지입니다.
4의 경우 임의의 random vector에서 특성 latent를 설정하고 콘텐츠 latent는 반대 도메인의 것을 이용합니다. 그 결과 나온 이미지는 랜덤한 특성을 지닌 이미지입니다.
cycle loss를 위한 이미지 생성

앞서 생성된 fake 이미지가 5을 통해, 특성 latent vector와 콘텐츠 latent vector 두 가지로 출력 됩니다.
앞선 1, 2과정처럼 특성 latent는 같은 도메인, 콘텐츠 latent는 반대 도메인에 해당하는 latent를 입력값으로 하여 각 Generator에 넣어줍니다. 이를 cycle 이미지라 명하고 본래 도메인 이미지와의 L1 loss를 계산하는데 이용합니다.
discriminator loss 항들
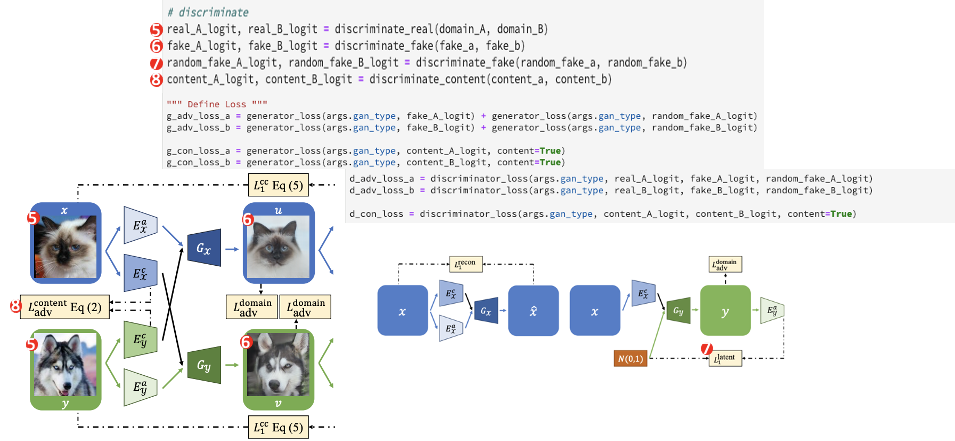
5은 실제 이미지 A, B를 실제라고 판별할 확률을 출력해냅니다. 6은 생성한 가짜 이미지를 가짜라고 판별할 확률을 출력합니다.
7은 앞서 임의의 벡터를 특성 latent vector값으로 주입하고, 반대 도메인의 콘텐츠 latent vector 값을 입력받아 임의로 생성된 이미지에 시행하는 과정입니다. 임의의로 생성된 이미지가 fake일 확률을 판별합니다.
마지막으로 8은 각각의 콘텐츠 latent vector가 콘텐츠에 속하는지 아니면 특성에 속하는지 판별되고, 콘텐츠에 속할 확률을 출력합니다.
이렇게 하면 DRIT++ 의 학습을 위한 loss 설계가 완료됩니다.



