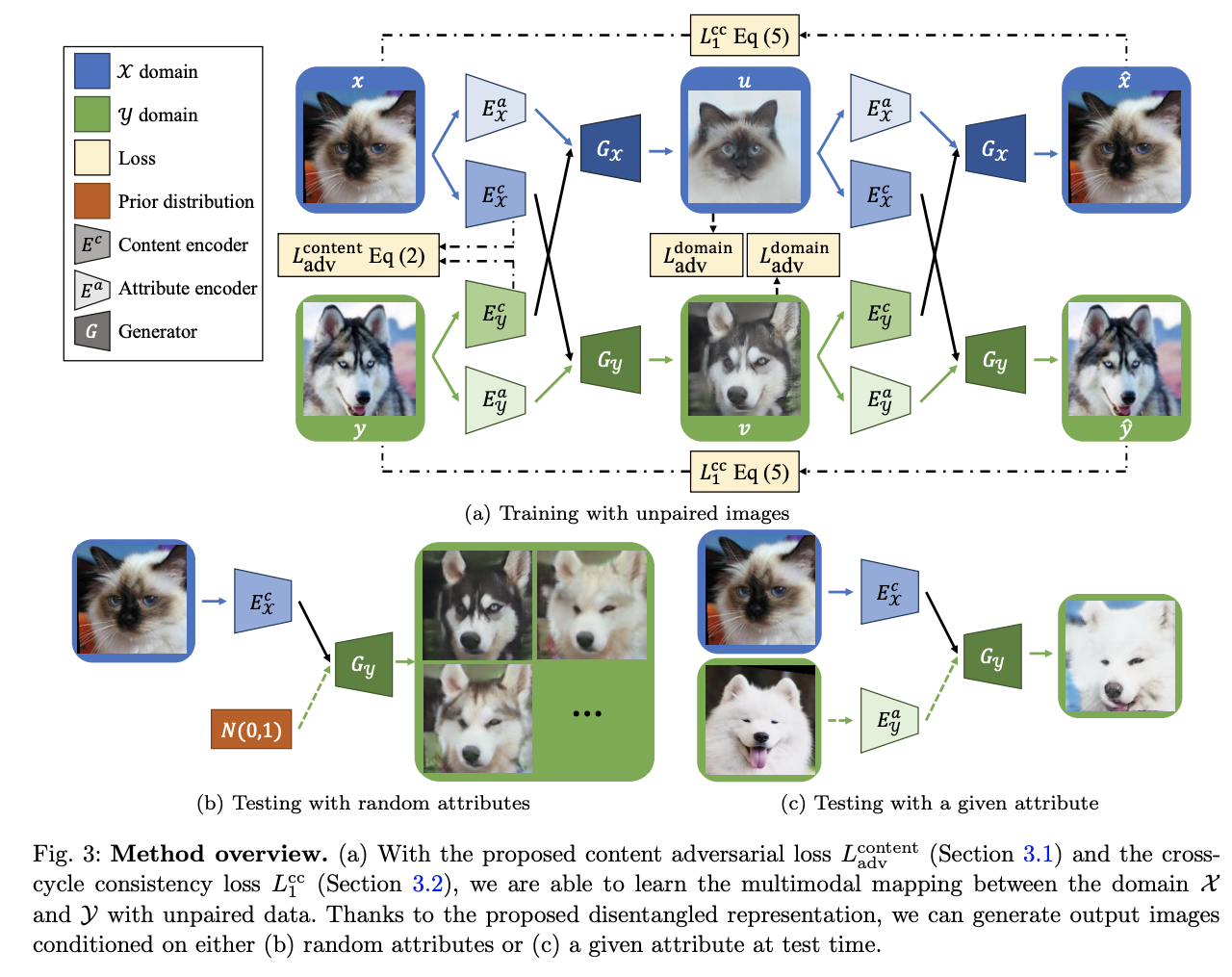

콘텐츠와 속성 인코더가 각각 있다. 두 벡터를 조건으로해서 $$ G_x $$ 는 이미지를 합성한다. 도메인 판별자 $$D_x$$ 는 이미지가 실제인지 합성된 이미지인지 판단해준다. 콘텐츠 판별자 $$D^c$$는 두 도메인 사이의 추출된 콘텐츠 표현을 구분하도록 훈련 받는다.

입력이미지를 공통된 콘텐츠 C 공간과 각 도메인마다 특정지어지는 특성 공간 Ax, Ay로 임베딩 시킨다.
representation dientanglement를 달성하기 위한 두 가지 전략 : 가중치 공유, 콘텐츠 판별자
두 도메인이 공통된 latent space를 공유한다고 가정하고, 콘텐츠 인코더 x,y 의 마지막 layer의 가중치를 서로 공유시킨다. 또 Generator x, y 의 첫번재 layer의 가중치를 공유시킨다. 이걸로 콘텐츠의 표현이 같은 공간에 맵핑되게 강제한 것이다.
그렇다고 두 도메인 사이에 같은 콘텐츠 표현을 함축하고 있단 것을 보장하진 않는다.
그래서 콘텐츠 판별자 $$D^c$$를 제안하는데, 이 판별자는 인코딩된 콘텐츠 특성 $${z_x}^c, {z_y}^c$$가 어떤 도메인에 속한지 구분해주는게 목표다. (콘텐츠 도메인인지 특성 도메인인지)
반면 콘텐츠 인코더는 인코딩된 콘텐츠 표현을 출력하는데, 이 표현은 해당 도메인이 콘텐츠 판별자에 의해 어떤 도메인인지 식별할 수 없게끔 학습된다. (콘텐츠 도메인인지 특성 도메인인지 알 수 없게)

일반적인 크로스 사이클 일치와는 달리, 제안된 크로스 사이클 제약은 사이클 reconstruction을 위해 disentangled 콘텐츠와 속성 표현을 이용한다.

두 가지 단계가 있다.
1. forward translation
이미지 x, y가 주어지면 이를 각각 $$\{{z_x}^c, {z_x}^a\}, \{{z_y}^c, {z_y}^a\}$$ 으로 인코딩 시킨다. 그리고 $${z_x}^a, {z_y}^a$$를 바꿔주고 Generator에 입력시켜 {u, v} (각각 이미지로 도메인 X, Y에 속함)를 생성한다.
2. Backward translation
이미지 u, v가 주어지면 이를 각각 $$\{{z_u}^c, {z_u}^a\}, \{{z_v}^c, {z_v}^a\}$$ 으로 인코딩 시킨다. 그리고 두번째 translation으로서
$${z_u}^a, {z_v}^a$$ 를 서로 바꿔주고 Generator에 입력시켜
x^, y^ (각각 이미지로 도메인 X, Y에 속함)를 생성한다.
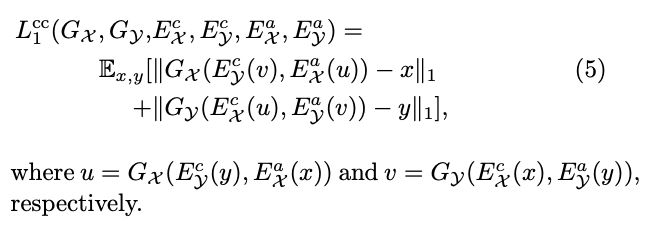
self reconstruction loss를 포함하면, 최종 loss는 아래 box와 같다.


'Data-science > 논문 읽기' 카테고리의 다른 글
| [논문 읽기] Learnable Triangulation of Human Pose -1 (0) | 2021.06.17 |
|---|---|
| [논문 읽기] DRIT ++ 코드와 함께 이해하기, 논문 설명 (0) | 2021.06.09 |
| [논문 읽기] Unpaired Image-to-Image Translationusing Cycle-Consistent Adversarial Networks (Cycle GAN 논문 핵심만 정리) (0) | 2021.06.03 |
| [논문 읽기] Adversarial Texture Optimization from RGB-D Scans - 1 (0) | 2021.06.02 |
| [딥러닝] Star gan v2 논문 읽기 (0) | 2021.05.16 |



