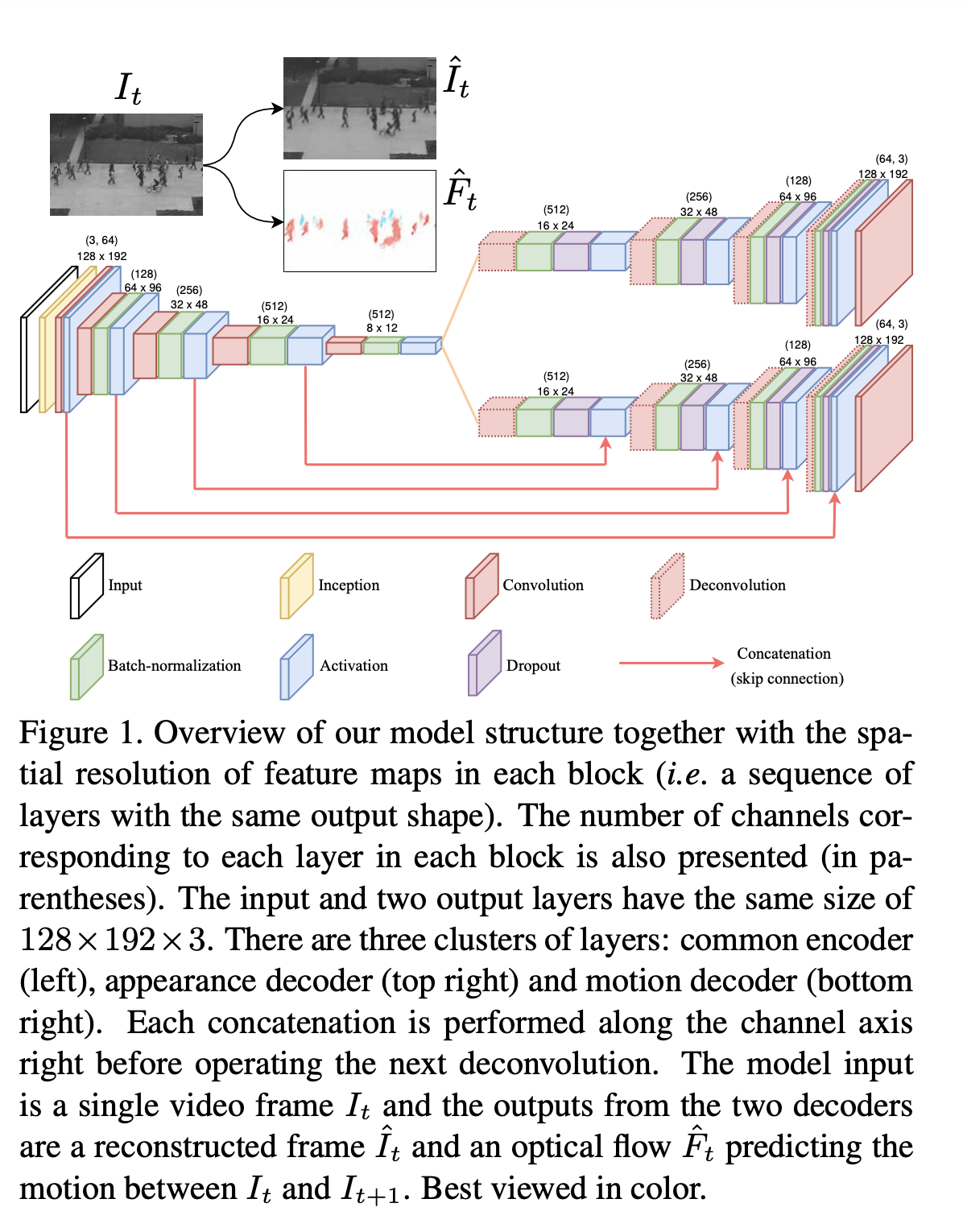
특정 시간 t의 비디오 프레임이 입력값으로 주어지면, 인코더를 통해 인코딩 된다.
그리고 디코더는 2개인데, 인코딩된 코드를 입력값과 같게 복원하는 디코더와, t와 t+1 시간 사이의 움직임을 예측하는 디코더로 이루어져있다.

원래 형상을 복원하는 appearance spatial structure에는 u-net의 skip connection을 사용하지 않음, 그렇게 되면 초기 입력 정보의 연결만 흘러보내게 되고, 인코딩을 제대로 학습하지 않을 수도 있기 때문이다. 모션 예측에는 skip connection을 이용 (초기 low level feature들인 엣지, 이미지 펫치 등을 전달하여 image translation 시 유용하기 때문이다.)
3.2. Appearance convolutional autoencoder

디코더에서 학습시 오버피팅을 막기위해 drop out 레이어를 추가해줬다.
loss는 intensity loss와 gradient loss 두 개로 이루어져있다. intensity loss는 당연히 정상 영상의 패턴을 학습하기 위해 l2 loss를 적용한 것이다. 그런데 이 것만 쓰면 복원된 영상에 blur가 일어난다. 이를 방지하기 위해 영상의 sharpness를 나타내는 gradient 정보의 차이를 최소한으로 학습하게 끔 하는 gradient loss를 정의한다. 이는 각 ground_truth와 pred 값의 gradient에 절댓값을 취하고 이 차이를 합한 것이다.
3.3. Motion prediction U-Net

3.4. Additional motion-related objective functio

GAN loss를 도입한다. Generator는 Figure1에 나타난 그림 전체이고, discriminator는 Figure2이다.


3.5. Anomaly detection

전체 픽셀 위치에대한 합 연산이나 평균 연산 때문에 작은 영역의 정보를 놓칠 수 있다. 그 작은 영역에서 비정상 이벤트가 일어나는데도 말이다. 전체 프레임 대신에 작은 패치에 대해 점수를 계산하는 방식을 도입했다. 하나는 이미지 복원 Intensity에 대한 것이고, 다른 하나는 예측 Flow에 대한 것으로 score S는 두 점수의 weighted sum으로 정의된다.

P~는 특정 패치의 flow score 값중 가장 큰 값의 인덱스로 이루어진 패치이다.
학습 데이터 n개에 대해 각 점수의 가중치는 각 점수를 계산한 평균값의 역수와 같다.
패치 사이즈는 슬라이딩 윈도우에 의해 결정되는데, 이는 컨볼루션 필터의 크기를 가령 16 x 16으로 이용하는 것으로 구현될 수 있다.

최종 프레임 레벨의 이상 탐지 점수는 최댓값을 분모로하고 특정 frame index의 값을 분자로 하는 값으로, normalization된 값이다.
비정상 프레임의 경우 추정된 점수가 정상 이벤트의 점수들과 비교해서 높게 나타날 것이다.

왼쪽이 입력 프레임과 그에 따른 시각적 flow, 중간이 복원된 프레임과 예측한 모션, 오른쪽이 예측 프레임 + 모션 에러, 모션에러를 나타낸다.



