
- Generator가 2개 있는데 $$\varepsilon $$와 G가 그것이다.
- $$\varepsilon $$은 인코더로 타임 시리즈 데이터를 latent space로 맵핑 시키는 역할을 하고, G는 반대로 디코더의 역할을 한다. $$C_x, C_z$$가 discriminator라고도 알려진 Critic 역할을 하는데, 전자는 실제 타임 시리즈 데이터와 디코더를 통해 생성된 타임 시리즈를 구별해준다. 후자는 latent space로 맵핑이 잘 이루어졌는지를 측정한다.
- Wasserstein loss (GAN loss)
첫 번째는 GAN loss인데 기존의 banila gan의 loss를 그대로 사용할 경우 mode collapsing 문제에 부닥치게 된다. 따라서 Wassertein loss를 이용한다.

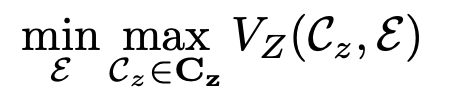
2. Cycle consistency loss
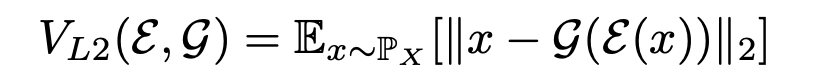
인코딩된 타임 시리지를 다시 디코딩하고 이를 원본 타임시리즈와 비교하는 loss로 l2 norm을 이용한다. z도 마찬가지로 cycle consistency loss를 구축하려 했으나 실험을 통해 효과가 없음이 발혀져 x에 대한 loss만을 이용한다.
3. full objective
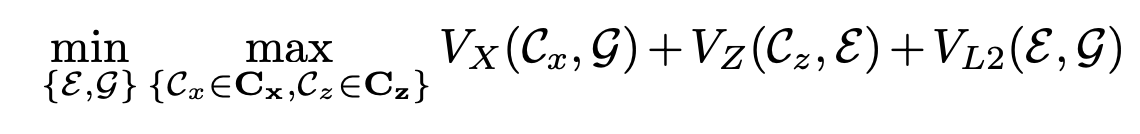
최종 loss는 위와 같다. V_x, V_z는 각각 x, z의 Wassertein loss를 나타내고, V_l2는 cycle consistency loss를 나타낸다.
A. Estimating Anomaly Scores using Reconstruction Errors
- 원본 타임 시리즈와 reconstucted된 타임 시리즈의 차이를 비교해서 비정상인 정도를 측정하는 방법을 소개한다.



- Reconstruction Errors를 이용해 비정상 점수(비정상인 정도, abnormaly score)를 측정하는 방법으로 세 가지를 제시했다.
- 하나는 간단히 point 끼리의 차이의 절대값을 계산하는 방식이고, 다른 하나는 타임 시리즈 그래프를 그리면 나타나는 아래의 면적의 차이를 비교하는 방식이다. 그리고 DTW 방법이 있는데 이는 두 개의 주어진 시퀀스 사이에 최적의 매칭을 계산하는 방법이다. 로컬한 리즌의 유사도를 개산하는 데 이용된다. 원본 타임 시리즈와 재구축된 타임 시리즈 원소 사이의 거리를 각 원소로 갖는 행렬 w를 정의하고, 두 곡선 사이의 최소 거리를 정의하는 w*(wrap path)를 찾는 방식으로 문제를 정의한다. 시작점과 끝점을 경계조건을 주고 연속 조건과 monotonicity? 조건도 추가해주면 위 수식과 같이 wrap path를 계산할 수 있다.
B. Estimating Anomaly Scores with Critic Outputs
Critic이 훈련되면 해당 타임 시리즈가 얼마나 realness 한 지를 바로 측정하는 데 사용할 수 있다.
크리틱의 값들에 kernel density estimation (KDE)를 적용시켜 부드럽게 만든 후, 최댓값을 취하는 방식이다.
C. Combining Both Scores
Reconstruction score가 높을수록, Critic 점수가 낮을수록 더 높은 비정상 점수를 나타낸다.
두 개를 조합하기 위해 각자의 Z score를 계산한 후 linear 하게 더해주거나 곱해준다. 두 방법 모두 좋은 결과를 가져왔다고 한다.

D. Identifying Anomalous Sequences
...



