403 error는 크롤링을 막아놓은 사이트에서 크롤링시 발생하는 에러이다.
"2021-02-09 23:27:33 [scrapy.spidermiddlewares.httperror] INFO: Ignoring response <403 http://bodyluv.kr/product/3%EC%B0%A8-renewal-%EB%B0%94%EB%94%94%EB%9F%BD-%EB%A7%88%EC%95%BD%EB%B2%A0%EA%B0%9C/44/category/1/display/2/?crema-product-reviews-1-page=1>: HTTP status code is not handled or not allowed"
해결법은 간단하다.
setting.py를 열고 USER_AGENT 부분을 아래와 같이 수정한다. 이후 잘 크롤링 된다. 200
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.95 Safari/537.36'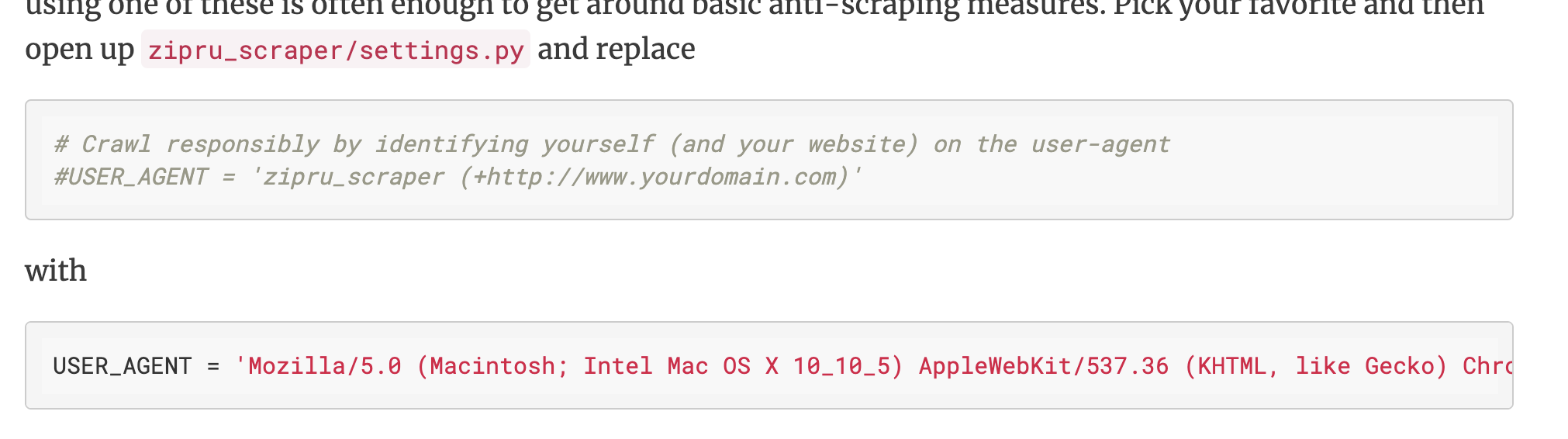
sangaline.com/post/advanced-web-scraping-tutorial/
Advanced Web Scraping: Bypassing "403 Forbidden," captchas, and more | sangaline.com
The full code for the completed scraper can be found in the companion repository on github. Introduction I wouldn’t really consider web scraping one of my hobbies or anything but I guess I sort of do a lot of it. It just seems like many of the things tha
sangaline.com
'Data handling > Web crawling' 카테고리의 다른 글
| DevToolsActivePort file doesn't exist error 해결법 (1) | 2021.02.19 |
|---|---|
| [selenium] js 동적 페이지 크롤링 하기 (주로 댓글) iframe, #document 해결 (0) | 2021.02.12 |
| [크롤링] 엄청 쉽고 간단한 크롤링 방법. 꿀팁. 라이브러리 필요 없음 (0) | 2020.09.29 |
| [오픈 Api 이용하기] 금융위원회_기업기본정보 python, 공공 데이터 (2) | 2020.07.01 |
| [크롤링] beautiful soup에 관하여, 내가 bs를 쓰지 않는 이유 (0) | 2020.06.26 |


