728x90
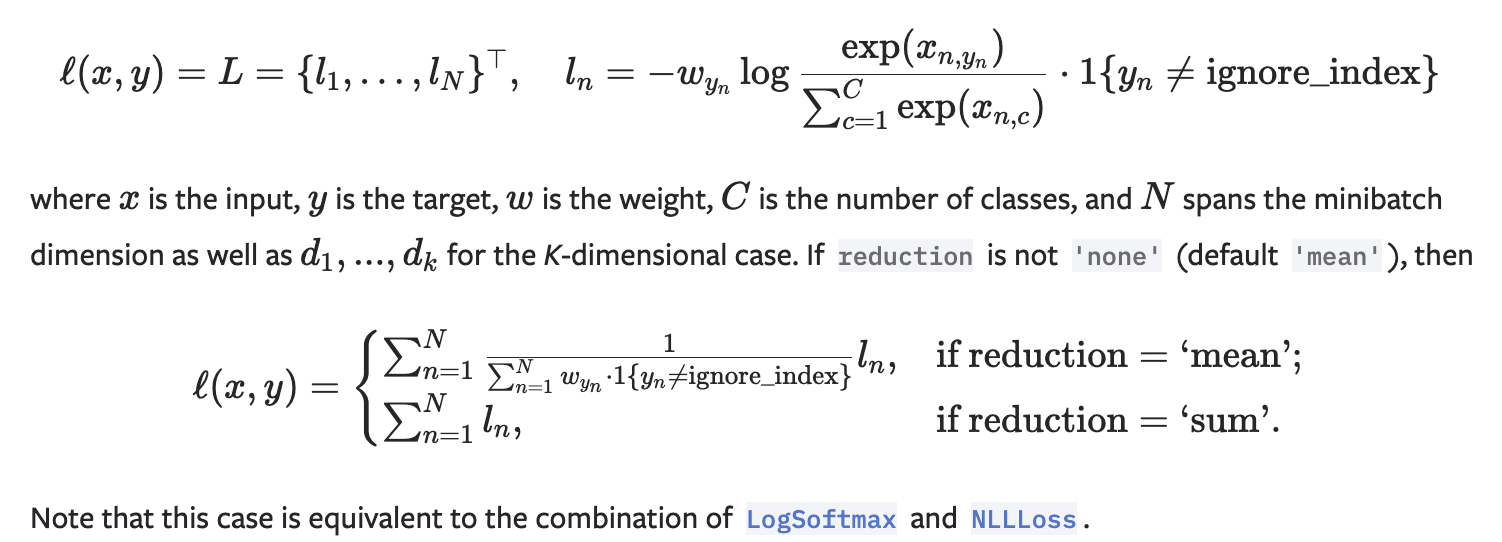
softmax가 이미 F.cross_entropy에 포함되어 있다. 따로 레이어에 추가히지 말자.
LSTM 구현 예제
1. return_sequences가 없을 때
hidden_dim = 75 #150
class SimpleLSTM(LightningModule):
def __init__(self, input_features, output_features, batch_first, num_classes):
super(SimpleLSTM, self).__init__()
self.lstm = nn.LSTM(input_size=input_features, hidden_size=output_features, batch_first=batch_first)
self.linear = nn.Linear(output_features, num_classes)
def forward(self, x):
out, (hn, cn) = self.lstm(x)
out = self.linear(out[:, -1, :])
# out = torch.softmax(out, dim=1)
return out
def training_step(self, batch, batch_idx):
x, y = batch
y_hat = self(x)
y = y.squeeze(dim=-1)
loss = F.cross_entropy(y_hat, y)
metrics={'loss':loss}
self.log_dict(metrics)
return loss
def validation_step(self, batch, batch_idx):
x, y = batch
logits = self(x)
y = y.squeeze(dim=-1)
loss = F.cross_entropy(logits, y)
acc = FM.accuracy(logits, y.long())
metrics = {'val_loss':loss, 'val_acc':acc}
self.log_dict(metrics)
return loss
def test_step(self, batch, batch_idx):
x, y = batch
logits = self(x)
y = y.squeeze(dim=-1)
loss = F.cross_entropy(logits, y)
acc = FM.accuracy(logits, y.long())
metrics = {'test_loss':loss, 'test_acc':acc}
self.log_dict(metrics)
return loss
def configure_optimizers(self):
return torch.optim.Adam(self.parameters())
model = ManyToOneLSTM(features, hidden_dim, batch_first=True, num_classes=num_classes)
summary(model, input_size=(4, sequence_length, features))
2. return_sequences가 있을 때 -> seqence channel 을 for루프를 돌며 loss를 계산 더해준다.
hidden_dim = 75 #150
class SimpleLSTM2(LightningModule):
def __init__(self, input_features, output_features, batch_first, num_classes):
super(SimpleLSTM2, self).__init__()
self.lstm = nn.LSTM(input_size=input_features, hidden_size=output_features, batch_first=batch_first)
self.timeDistributed = TimeDistributed(nn.Linear(output_features, num_classes), batch_first=batch_first)
def forward(self, x):
out, (hn, cn) = self.lstm(x)
out = self.timeDistributed(out)
return out
def training_step(self, batch, batch_idx):
x, y = batch
y_hat = self(x)
y = y.squeeze(dim=-1)
loss, acc = 0, 0
for i in range(x.shape[1]):
loss += F.cross_entropy(y_hat[:, i, :], y[:, i])
acc += FM.accuracy(y_hat[:, i, :], y[:, i].long())
loss /= x.shape[1]
acc /= x.shape[1]
metrics={'loss':loss, 'acc':acc}
self.log_dict(metrics)
return loss
def validation_step(self, batch, batch_idx):
x, y = batch
logits = self(x)
y = y.squeeze(dim=-1)
loss, acc = 0, 0
for i in range(x.shape[1]):
loss += F.cross_entropy(logits[:, i, :], y[:, i])
acc += FM.accuracy(logits[:, i, :], y[:, i].long())
loss /= x.shape[1]
acc /= x.shape[1]
metrics = {'val_loss':loss, 'val_acc':acc}
self.log_dict(metrics)
def configure_optimizers(self):
return torch.optim.Adam(self.parameters())
model = ManyToManyLSTM(features, hidden_dim, batch_first=True, num_classes=num_classes)
summary(model, input_size=(4, sequence_length, features))LSTM 구현 끝.



