
그룹별 점수 -> 순위화
위와 같이 카테고리별로 점수가 있다고 했을 때, 카테고리 별로 점수를 rank화 시키고 싶을 때 어떻게 해야 할까?
방법은 간단하다.
1. groupby를 이용해 특정 group별로 묶어준다.
2. groupby 객체에 rank 함수를 적용해준다.

주의할 점이 있다.
위와 같이 하면 기본적으로 등수에 소수점이 섞인 값이 나온다.

이유는 rank method의 방법의 default 값이 'average' 이기 때문이다.

내가 원하는 건 등수이지 소수점이 아니다. 보통 쓰는 방법은 'min'이다. 이렇게 하면 공동 2등이 있을 경우, 3등은 없고 4등부터 나온다.


점검
카테고리별로 등수, 순위가 제대로 메겨졌는지 확인해보자.
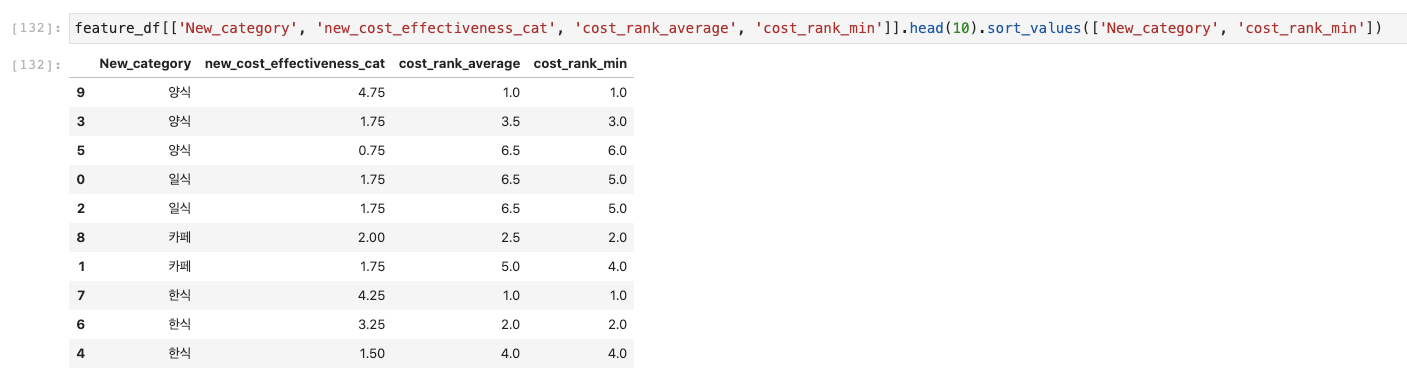
상위 10개만 뽑았기에 순위가 좀 달라 보일 수 있지만 제대로 메겨졌다.
참고 사이트
pandas.Series.rank — pandas 1.1.2 documentation
max_rank: setting method = 'max' the records that have the same values are ranked using the highest rank (e.g.: since ‘cat’ and ‘dog’ are both in the 2nd and 3rd position, rank 3 is assigned.)
pandas.pydata.org
https://rfriend.tistory.com/461
[Python pandas] DataFrame, Series에서 순위(rank)를 구하는 rank() 함수
이번 포스팅에서는 Python pandas의 DataFrame, Series 에서 특정 변수를 기준으로 순서를 구할 때 사용하는 rank() 함수를 소개하겠습니다. 순위(Rank)는 정렬(Sort)와 밀접한 관련이 있는데요, 참고로 Python��
rfriend.tistory.com
'Data handling' 카테고리의 다른 글
| 기타 에러 ImportError: cannot import name 'StringIO' (0) | 2020.10.28 |
|---|---|
| [데이터 전처리] str to json 어떻게 바꾸지? str 형식의 text를 json으로 변환 (0) | 2020.09.29 |
| [인코딩 방식] 웹에서 얻은 데이터가 안열릴때 (0) | 2020.09.03 |
| [pandas] str으로 나타내진 datetime 을 mean 연산 가능한 형식으로 변환하기 (0) | 2020.06.26 |
| [크롤링 삽질] selenium 스크롤 다운 안될때 꿀팁 (2) | 2020.06.26 |


