728x90
image = cv2.imread('C:\\Users\\SGSDEV\\detection\\original\\6666.jpeg')
img = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
_, src = cv2.threshold(img, 200, 255, cv2.THRESH_BINARY_INV)
cnt, labels, stats, centroids = cv2.connectedComponentsWithStats(src)
dst = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR)
imgs = []
for i in range(1, cnt): # 각각의 객체 정보에 들어가기 위해 반복문. 범위를 1부터 시작한 이유는 배경을 제외
(x, y, w, h, area) = stats[i]
# print(x, y, w, h, area)
# 노이즈 제거
if area < 50000:
continue
imgs.append(image[y:y+h,x:x+w])
dst = cv2.rectangle(dst, (x, y, w, h), (255, 0, 0), thickness=5)dst = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR)
imgs = []
for i in range(1, cnt): # 각각의 객체 정보에 들어가기 위해 반복문. 범위를 1부터 시작한 이유는 배경을 제외
(x, y, w, h, area) = stats[i]
# 노이즈 제거
if area < 50000:
continue
imgs.append(image[y:y+h,x:x+w])
dst = cv2.rectangle(dst, (x, y, w, h), (255, 0, 0), thickness=5)패딩한 후 이미지 저장 (cv2.copyMakeBorder 를 이용한다)
[OpenCV-Python Tutorials 07] 이미지에 대한 기본 작업
[OpenCV-Python Tutorials 07] 이미지에 대한 기본 작업 모든 파일은 Github에서 확인 할 수 있습니다. 목표 배울 내용: 픽셀 값에 액세스 및 수정 이미지 속성에 액세스 이미지 영역 설정 (ROI: Region of Image)
jacegem.github.io
for idx, img in enumerate(imgs):
if img.shape[0] > 0 and img.shape[1] > 0:
img = cv2.copyMakeBorder(img, 500, 500, 500, 500, cv2.BORDER_CONSTANT, value=[230, 230, 230])
cv2.imwrite(f'{idx}_.png', img)각각 잘라서 저장하는 것도 좋은데, 과정을 시각화를 해본다.
이미지 사이즈가 커서 figsize를 크게 주었다.
plt.figure(figsize=(30,45))
plt.subplot(3, 1, 1)
plt.imshow(image,'gray')
plt.xticks([])
plt.yticks([])
plt.subplot(3, 1, 2)
plt.imshow(src, 'gray')
plt.xticks([])
plt.yticks([])
plt.subplot(3, 1, 3)
plt.imshow(dst)
plt.xticks([])
plt.yticks([])
plt.show()결과는



정확히 객체 부분만 잘라준다.
## 패딩을 한 이유는 딥러닝에서 객체를 분류하기 위해서이다. 객체만 확대해서 본 걸 학습하지 않아 모델에겐 어려울 수 있다. 그래서 학습 데이터와 최대한 유사한 데이터를 제공해준다.
딥러닝 디텍션 결과
모델을 앞선 포스트에서 말했던 것처럼 efficientDet을 이용하였다.


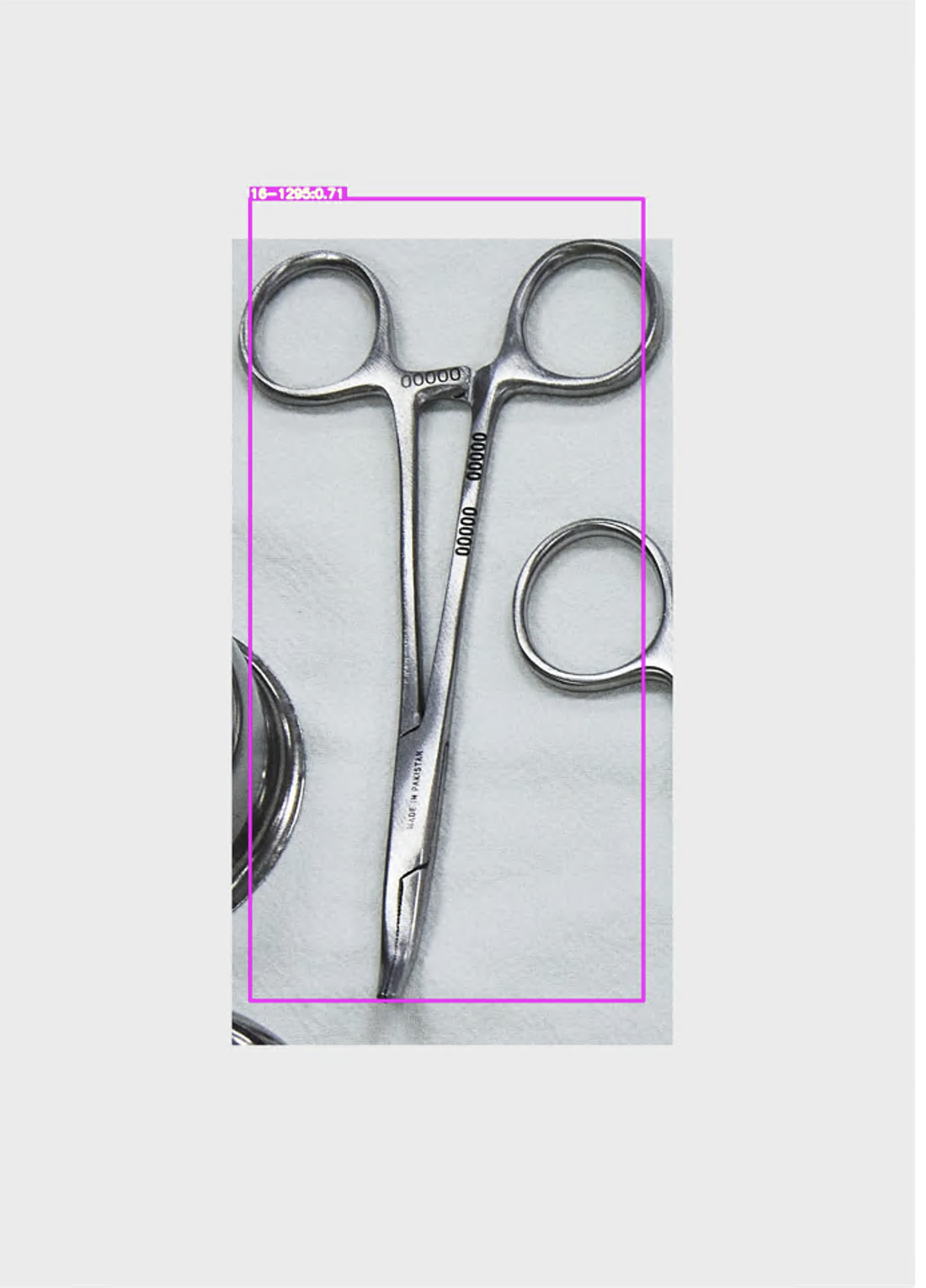
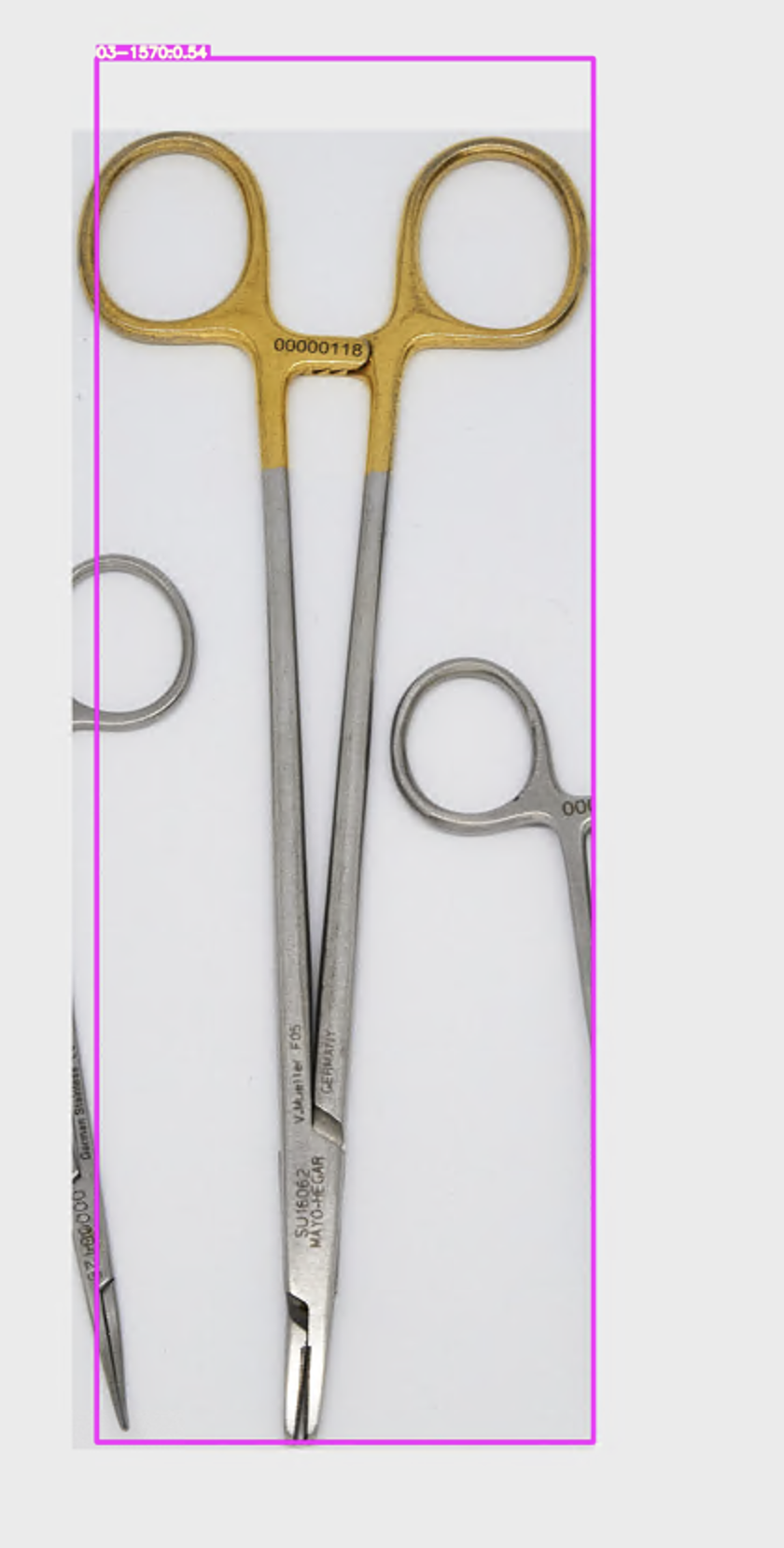

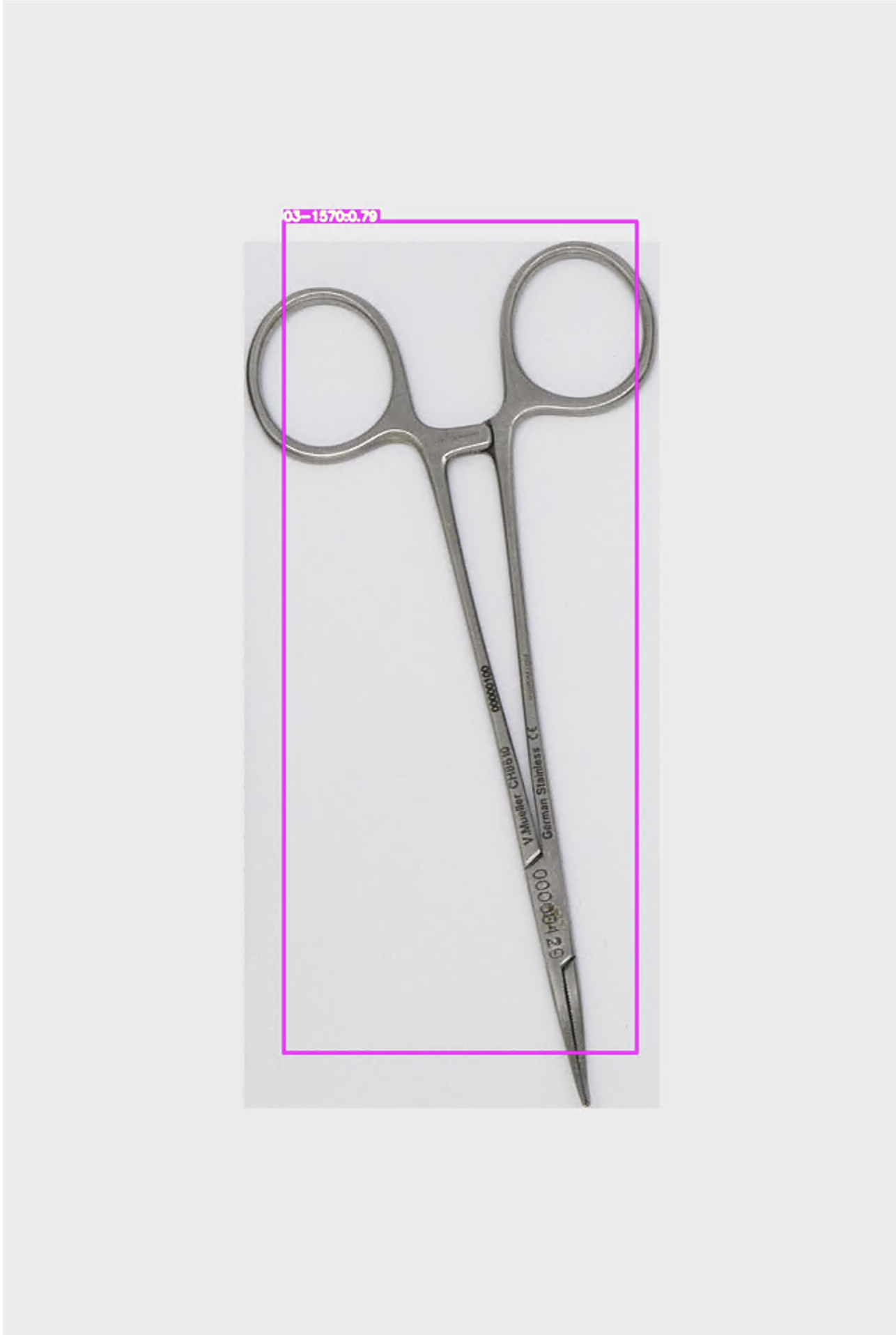
결과는 만족스럽다. 분류를 잘 해낸다. 훌륭하다~~~
'Data-science > deep learning' 카테고리의 다른 글
| [논문 읽기] EfficientDet: Scalable and Efficient Object Detection (0) | 2021.11.18 |
|---|---|
| [torch] RuntimeError("{} is a zip archive 에러 해결 방법 (0) | 2021.11.08 |
| efficientDet을 이용한 detection, deeplearning (0) | 2021.08.28 |
| [detection] 이미지 labeling이 이상하다 싶지만 정상일 때 해결방법. PIL Image rotated 회전시키는 녀석. (PIL image 쓸데 없이 고성능) (0) | 2021.08.28 |
| [딥러닝] Graph2Vec 4가지 특징 (0) | 2021.05.04 |



