728x90
논문



2D Image → 3d image
keypoints를 다시 projection했을 때 발생하는 reprojection loss를 최소화 하는 게 핵심
이걸 가능하게 하기위해 적대적으로 학습함 (사람의 체형이나 포즈 파라미터가 real 인지 아닌지를)
2d keypoint detection에 의존하지 않고 이미지 픽셀에서 바로 3d 파라미터(체형, 포즈)를 추론한다.
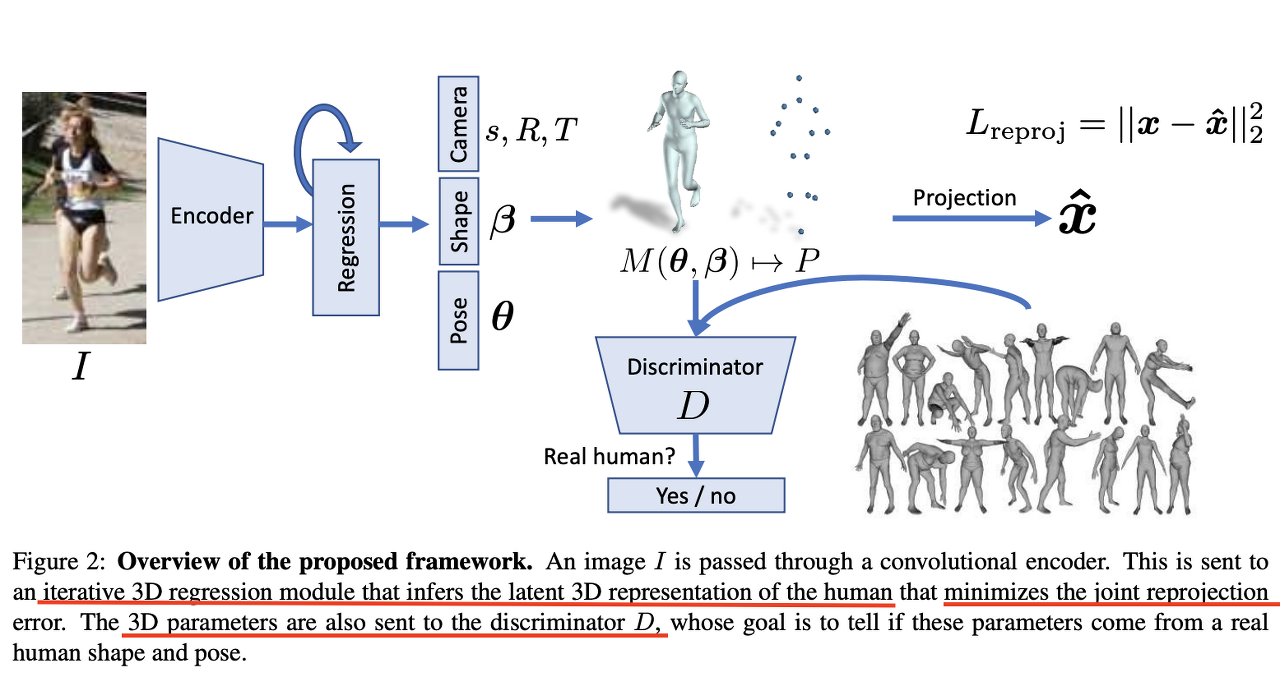
전체적인 기술 설명
- 이미지가 CNN을 통해 인코딩된다. 인코딩된 latent vector는 3차원 회귀(regression) 모듈에 보내진다. 이 모듈에서 사람의 3차원 형상을 표현하는 걸 배운다.
- 이 때 회귀모듈에서 나온 3차원 형상을 표현하는 latent vector(s, R, T, 베타, 세타)들은 reprojection error를 최소화 시키는 방식으로 추론된다.
- 자세한 설명은 없다. 내 생각엔 위 latent vector로 3차원 형상을 만들고 이걸 2차원으로 다시 reprojection하면 나오는 keypoints들이 있다. 이걸 x^라 하는듯. 이것과 본래 label (2d keypoints) x와의 오차를 최소화 시키는 방식으로 학습되는 것 같다.
- 3원 형상을 표현하는 latent vector들은 Discriminator로 전달된다. 이때 이 벡터들이 표현하는 형상이 사람의 pose나 shape이 아닐 수 있다. (가령 관절이 뒤틀린다든지…) 이런 상황을 막기 위해 Discriminator를 학습 시킨다. 그 결과 latent vector는 올바른 모습을 표현할 수 있는 것이겠고.

기존 기술과의 차이점
- 이미지 특징에서 바로 3D 모델링을 위한 파라미터를 추론할 수 있다. (이전 접근 방식은 2D keypoints로 부터 추론한 것) 그래서 2 단계로 학습할 필요가 없어졌다.
- 뼈대 뿐만이아니라 mesh를 출력으로 한다.
- end-to-end로 학습한다.
- 2d에 매칭되는 3d 데이터 없이도 적절한 결과물을 생성할 수 있다.
















