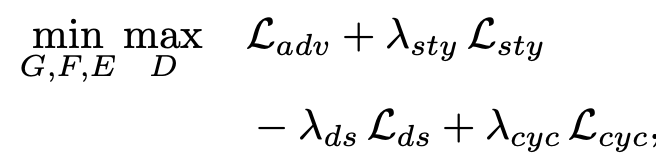X, Y 도메인에 대해 X 도메인에 속한 이미지를 x, Y 도메인에 속한 이미지를 y라하자.
- 목표 : x에 대응되는 각 y 도메인의 이미지를 생성 시키는 하나의 Generator를 훈련시키는 것
각 도메인의 스타일 공간에서 학습된, specific한 스타일 벡터를 생성시키고 G가 스타일 벡터를 반영하도록 훈련한다.
4가지 모듈이 있다. Generator(생성자), Mapping network(맵핑 네트워크), Style Encoder (스타일 인코더), Discriminator(판별자)

- 생성자 : 생성자는 이미지 x를 맵핑 네트워크 F를 통해 주어지거나 스타일 인코더 E를 통해 주어진, 특정 스타일 벡터 s를 반영하여 G(x, s)로 tranlsation 시킨다. s를 생성자에 주입하기 위해 AdaIn을 사용한다. s는 특정 도메인 y의 스타일을 표현하도록 설계되었고, 이건 생성자는 y를 주입받을 필요 없이 모든 도메인의 이미지를 합성할 수 있도록 한다.
- 맵핑 네트워크 : z라는 잠재 벡터와 도메인 y 이미지가 주어지면 맵핑 네트워크 F는 스타일 코드 s를 만든다. s = F_y(z) 에서 F_y는 y 도메인에 대응되는 F의 출력값을 의미한다. F는 MLP로 이루어져있고, 각 출력값은 모든 도메인에 해당하는 스타일 코드들을 제공한다. F는 다양한 스타일 코드를 생성할 수 있는데, Z에서 잠재 벡터를, Y에서 y를 무작위로 샘플링 함으로써 가능하다. 멀티 테스크 아키텍쳐는 F로 하여금 효율적, 효과적으로 모든 도메인의 스타일 표현을 학습할 수 있도록 한다.

- 스타일 인코더 : 이미지 x와 해당하는 도메인 y가 주어지면 인코더는 x의 슽타일을 추출한다. E_y(x), E_y는 y 도메인에 해당하는 E의 출력값을 의미한다. F(맵핑 네트워크)와 유사하게 작용한다. 다양한 레퍼런스 이미지를 이용하여 다양한 스타일 코드를 만들 수 있고, 이건 생성자로 하여금 레퍼런스 이미지 x의 스타일을 반영하는 출력물을 합성할 수 있도록 한다.
- 판별자 : 판별자의 출력값도 여러개인데, 각 브런치 D_y는 이진 분류를 학습한다. 이진 분류에선 이미지 x가 도메인 y의 진짜 이미지인지 혹은 생성자에의해 생성된 가짜 이미지인지를 결정한다.

Adversarial objective

Style reconstruction

Style diversification

Preserving source characteristics

Full objective